Abstract
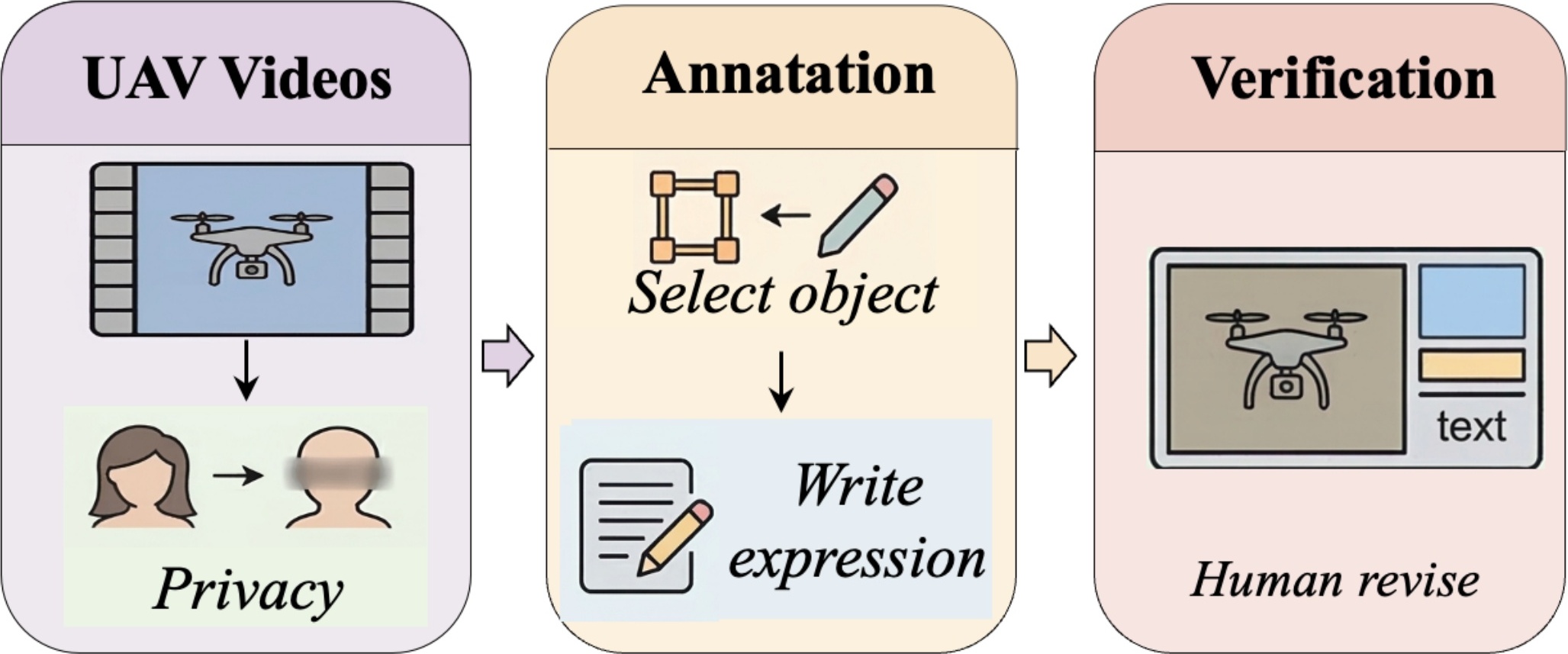
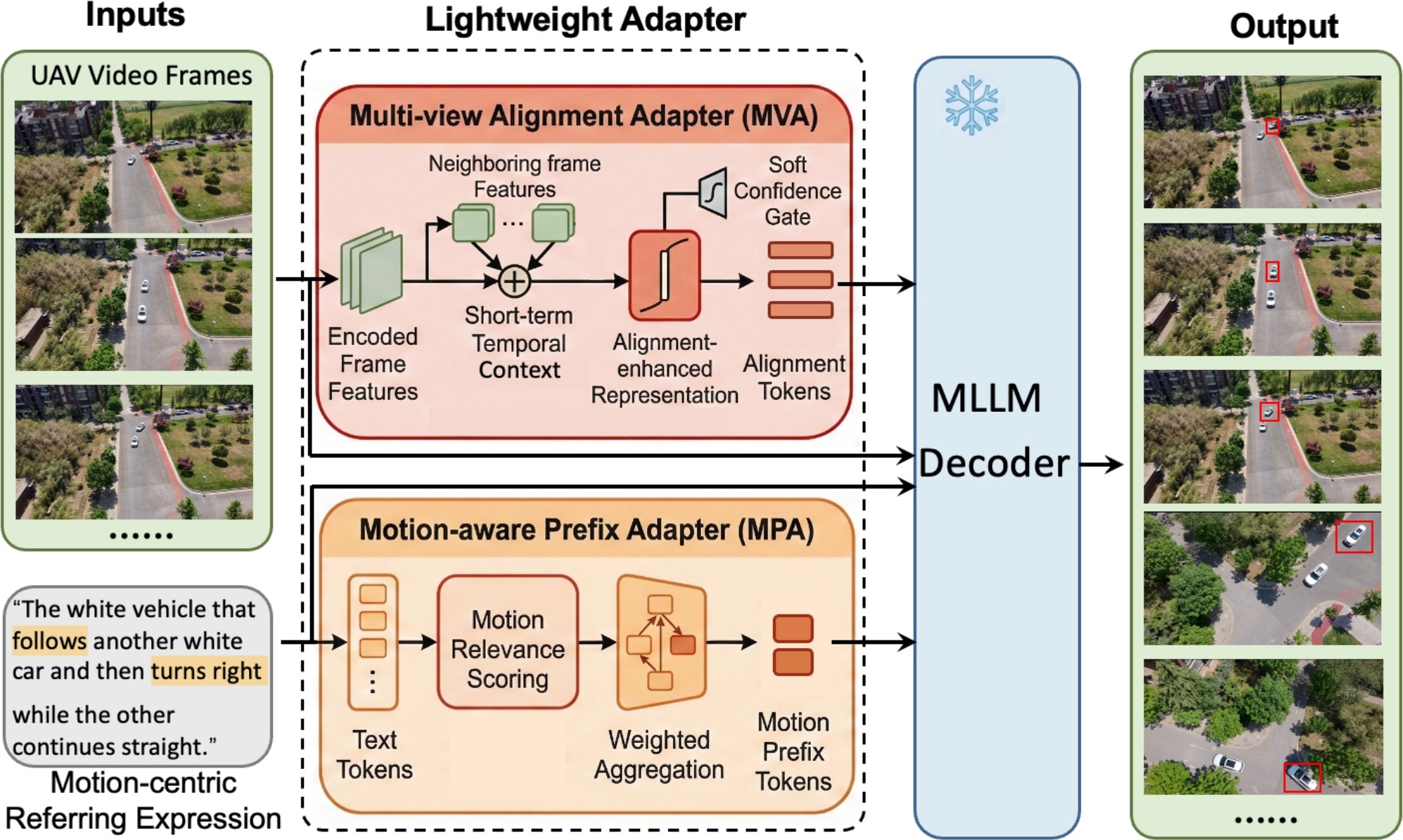
UAV visual grounding in real-world applications requires localizing a target referred to by language while both the target and the UAV move. Existing UAV grounding datasets mainly focus on images, while the few video-based benchmarks are still dominated by appearance and spatial cues. As a result, they do not adequately capture two key challenges: motion-centric grounding and drastic cross-view appearance changes caused by UAV ego-motion. To address this gap, we introduce MoRe-UAV, a large-scale benchmark for motion-aware visual grounding in UAV videos. MoRe-UAV contains 22,225 video-expression pairs and 7,415,622 annotated frames, covering diverse aerial scenes with moving targets and substantial viewpoint changes. We build the dataset through a scalable human-in-the-loop pipeline for efficient annotation with quality control. We establish an initial benchmark on MoRe-UAV with spatio-temporal video grounding methods, multimodal large language models, and hybrid MLLM+tracking pipelines. We further provide a stronger baseline with a Motion-aware Prefix Adapter and a Multi-view Alignment Adapter to enhance motion reasoning and cross-view alignment. Experiments show that existing methods struggle on MoRe-UAV and remain far below human performance, highlighting substantial room for future research on motion-aware and multi-view grounding in UAV videos.